SELF PRE-TRAINING WITH MASKED AUTOENCODERS FOR MEDICAL IMAGE CLASSIFICATION AND SEGMENTATION
主要目的
脑肿瘤的存在通常会导致肿瘤周围微环境的额外变化,包括水肿,脑组织的结构变化,和血管化增加。假设对上下文信息学习执行严格的要求可以改善深度学习-医学图像分析。
较早较简单的MAE在3D分割上的应用。
数据集
胸部X光(CXR14)、BTCV上的CT多器官分割和MRI脑肿瘤分割(BraTS)
模型框架
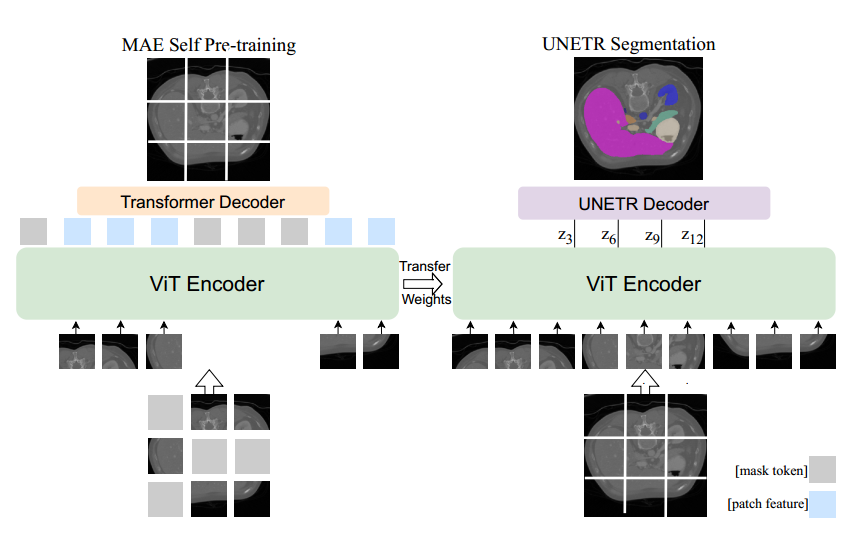
使用MAE对ViT编码器进行预训练。将补丁的随机子集输入编码器,然后Transformer解码器重建完整图像,传输预训练的ViT权重以初始化分割编码器。
本篇文章没有区分不同通道,使用Token:B×T×D(B:批大小, T:token数, D:特征维度),pretrain过程中:
X射线图像:直方图均衡化后从原始的256 × 256图像中随机翻转和裁剪224 × 224区域。
BTCV:裁剪-175和250之间的原始值,并在[0,1]内重新缩放范围。在预训练和微调过程中,我们随机翻转和裁剪96×96×96体积作为输入。
BraTS:实例归一化,在预训练和微调中,我们随机翻转和裁剪128 × 128 × 128的体积。
实验结果
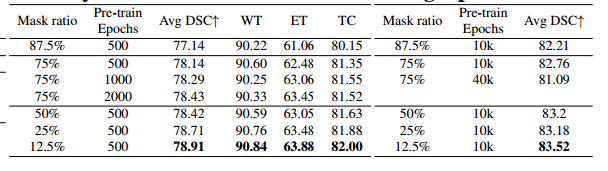
给出的结果是BraTS在12.5%掩码率时候效果最好,但是只测试了单个数据集,实际上本文最后使用的还是原MAE的75%mask。
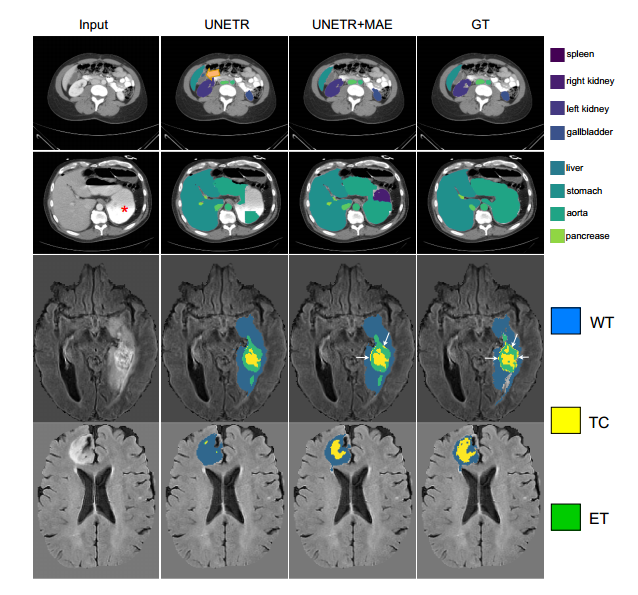
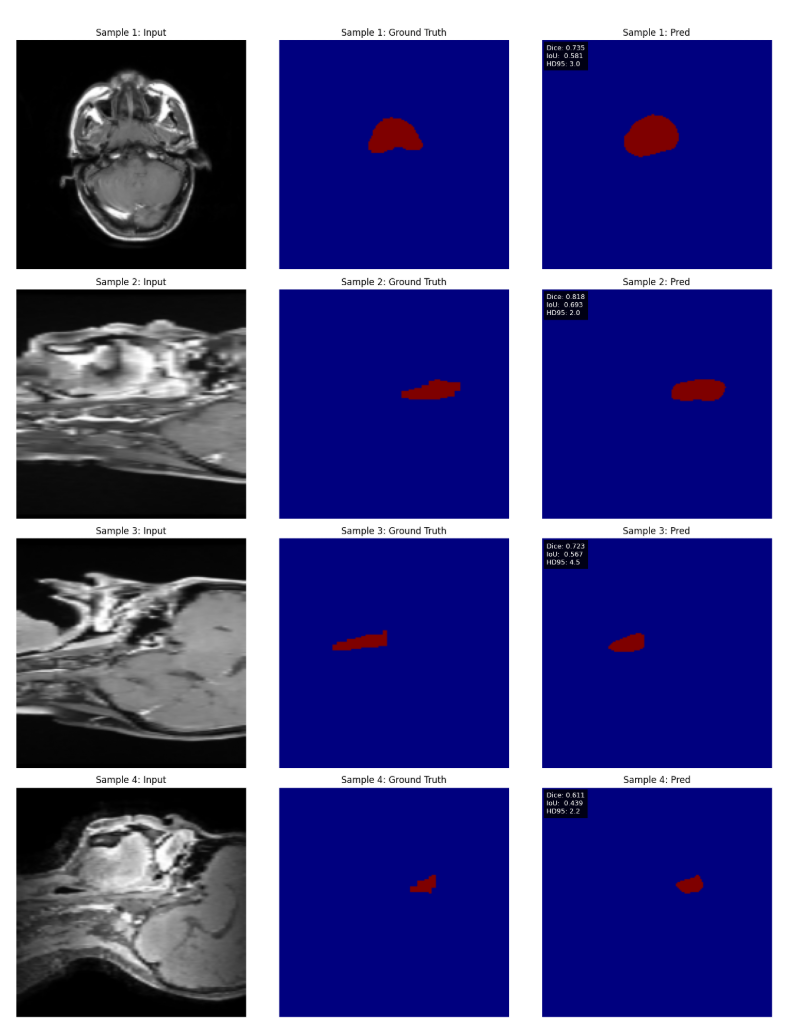
BTCV:前两行 BraTS:后两行
在没有MAE预训练的情况下,坏死的核心节段几乎不存在。
SELF PRE-TRAINING WITH ADAPTIVE MASK AUTOENCODERS FOR VARIABLE-CONTRAST 3D MEDICAL IMAGING
主要目的
现实中的磁共振成像研究常包含可变数量的3D图像(如T1、T2加权、FLAIR等),且不同病例的对比度类型和数量可能因临床协议或诊断需求而异。
能够在训练和测试过程中处理可变数量的输入图像,提高模型的灵活性和适应性,以不同的对比度真实的世界的临床数据。
使用可变数量的3D输入对比进行自我预训练,并最大限度地提高数据可用性。
数据集
364名受试者用于预训练,1648名受试者的子集用于训练,使用193个验证对象和215个测试对象进行微调,共45,374 张图像,主要是急性/亚急性脑梗死区域,手动分割时主要使用T2加权图像来判断。
Adaptive Masked Autoencoders模型框架
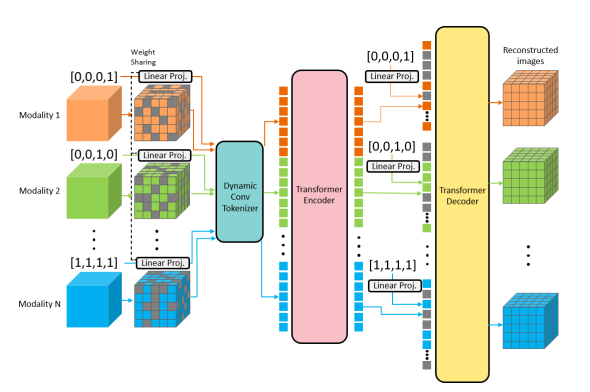
动态标记化 (Dynamic Tokenization):每个输入的3D模态(如T1加权、T2加权)首先被划分为3D块。每个模态都有一个专用的动态卷积层。该层的权重和偏置由一个可学习的模态特定向量生成。
这里输入时候生成的模态向量m
i通过可学习的线性投影,拆分成wconv和bconv,用于更新动态卷积层的权重和偏置。序列化与编码:所有模态的未掩码块被拼接成一个长序列,并输入标准Transformer编码器。每个块会加入位置编码(指示其在3D空间中的位置)和模态编码(指示它来自哪个模态)。
假设我们有一个单一的3D医学图像(例如一个CT扫描体积)。其张量形状为 [1, C, D, H, W]。这里的维度含义是:
1:批次大小(Batch Size),表示一次处理1个样本。C:输入通道数(Input Channels),例如单模态的灰度图像。D, H, W:分别表示体积的深度、高度和宽度
动态卷积标记化
- DCT使用一个3D卷积层,其关键参数设置为:
kernel_size = (patch_size_d, patch_size_h, patch_size_w)stride与kernel_size完全相同。out_channels = E(嵌入维度,例如192或768)。 - 卷积运算后,输出特征图的形状为 [1, C, E, D’, H’, W’]。其中:
D’ = D / patch_size_d
H’ = H / patch_size_h
W’ = W / patch_size_w 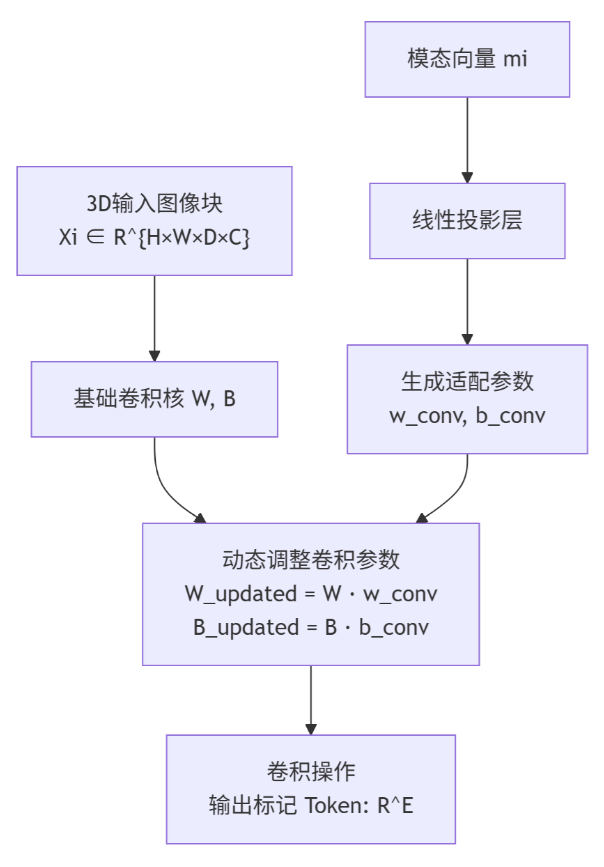
为了将数据送入Transformer编码器,需要将空间维度(D’, H’, W’)展平(Flatten)为一个序列长度(Sequence Length)N。
具体操作是:X_flat = X_conv.view(1, E, -1),得到形状 [1, E, N],其中 N = D' * H' * W'。
随后,为了符合Transformer的输入要求(序列维度在前),需要执行转置操作:X_tokens = X_flat.transpose(1, 2),最终得到形状为 [1, N, E]的张量。
这个 [1, N, E]的张量就是流程图中的“序列化标记 Tokens”,其中包含了 N个标记,每个标记是 E维的向量。
在下游任务(如分割)中的适配:
AMAE预训练后,其编码器可用于下游任务。针对可变长度的令牌序列,论文引入了一个**自适应最大池化层 (adaptive max pooling layer)**。
该层将可变数量Token:B×N×T×D(B:批大小, N:模态数, T:token数, D:特征维度)
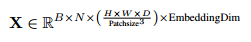
池化为一个固定大小的张量X:B×T×D,从而可以被标准的分割解码器(如UNet形状的解码器)处理。
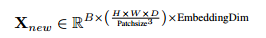
另一种方法使用原始的UNETR模型。所有来自不同模态的图像都沿着通道维度连接。如果缺少任何输入模态,则使用零填充张量。我们将预训练的ViT编码器的权重从预训练转移到UNETR编码器。(核心组成部分都是Vision Transformer块)
实验结果
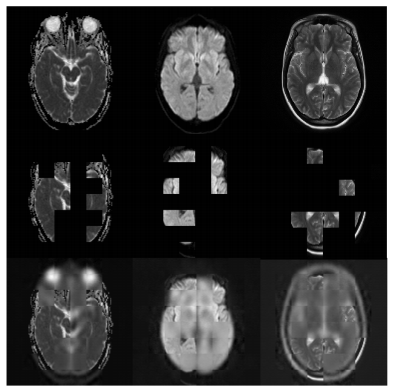
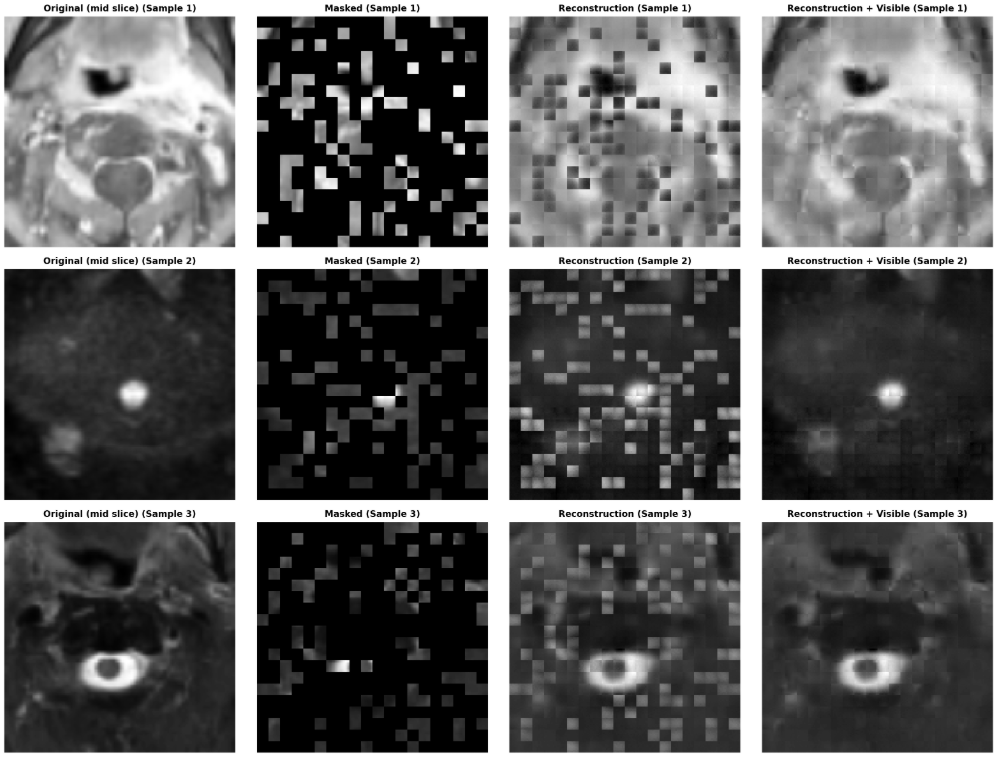
MAE可以从随机上下文中恢复已删除的数据。恢复的可见块看起来模糊,因为L2损失仅应用于掩蔽块。这是3D医学图像自我预训练的已知现象。MAE的目标不是产生高质量的重建,而是提取有用的特征以帮助下游任务。
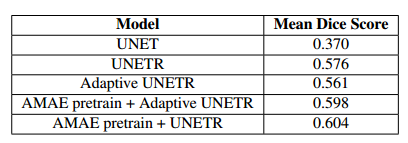
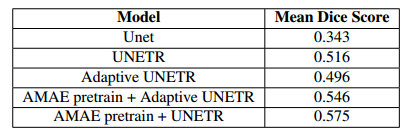
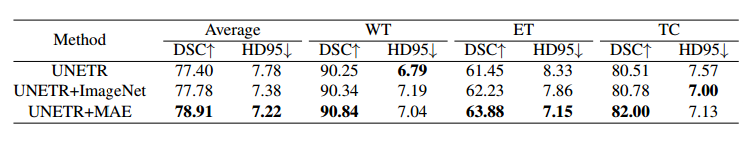
与不具有预训练权重的相应模型相比,应用预训练权重时的分割结果存在显著差异。